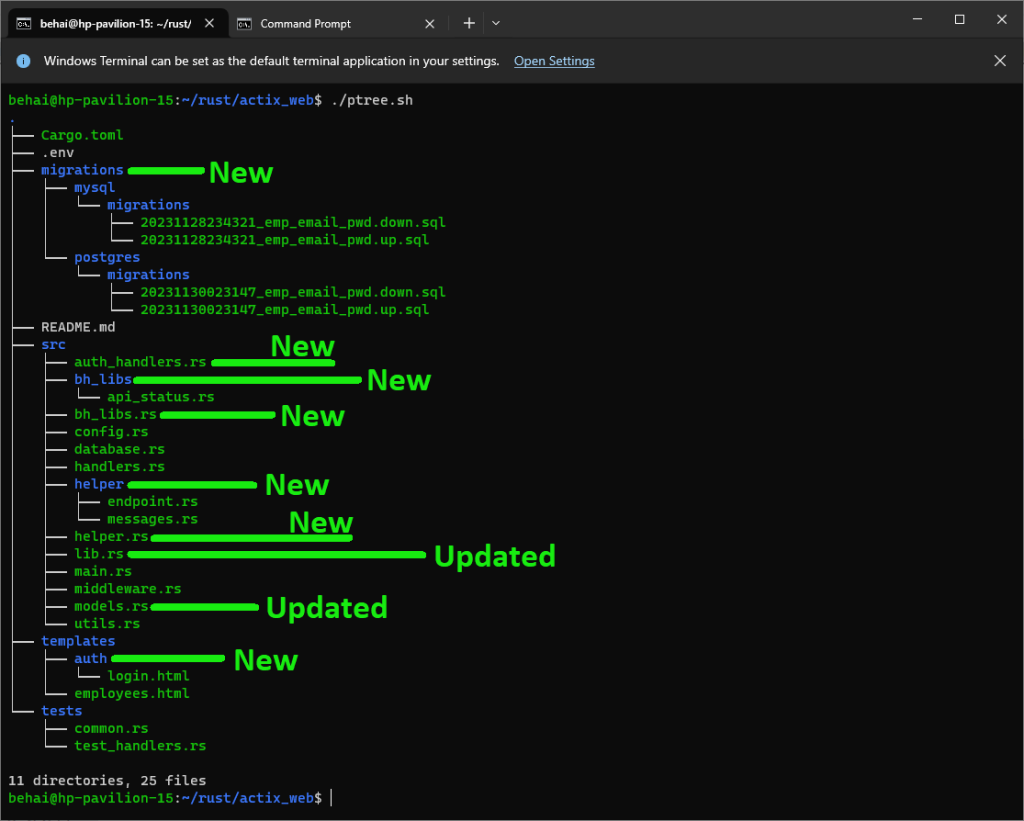
This component is based on a concept I previously implemented using Delphi and later PHP. Essentially, it consists of base classes representing database tables, equipped with the ability to interact with databases and implement generic functionalities for CRUD operations.
While learning the Flask framework, I found the conventional approach of accessing the database layer through the Flask application instance uncomfortable. In my previous projects, the database layer has always remained independent of other layers. The business layer ensures data validity and then delegates CRUD operations to the database layer. The UI layer, whether a desktop application or web client, communicates solely with the business layer, never directly accessing the database layer.
In
SQLAlchemy,
models representing database tables typically subclass
sqlalchemy.orm.DeclarativeBase
(this class supersedes the
sqlalchemy.orm.declarative_base
function).
Accordingly, the abstract base class in this
database wrapper component
is a
sqlalchemy.orm.DeclarativeBase
subclass, accompanied by another custom base class providing additional dunder methods.
Further subclasses of this abstract base class implement additional functionalities. Application models inherit from either the ReadOnlyTable or the WriteCapableTable base classes.
Application models are required to implement their own specific
database reading methods. For example, selecting all customers with the
surname Nguyễn.
The Database class is responsible for establishing connections to the target database. Once the database connection is established, application models can interact with the target database.
🚀 The full documentation can be found at https://bh-database.readthedocs.io/en/latest/.
Next, we will explore some examples. 💥 The first two are simple, single-module web server applications where the web layer directly accesses the database layer. Although not ideal, it simplifies usage illustration.
The latter two examples include complete business layers, where submitted data is validated before being passed to the database layer for CRUD operations.
❶ example.py: A Simple Single-Module
Flask Application.
● Windows 10: F:\bh_database\examples\flaskr\example.py
● Ubuntu 22.10: /home/behai/bh_database/examples/flaskr/example.py
from sqlalchemy import (
Column,
Integer,
Date,
String,
)
import flask
from bh_database.core import Database
from bh_database.base_table import WriteCapableTable
from bh_apistatus.result_status import ResultStatus
SQLALCHEMY_DATABASE_SCHEMA = 'employees'
SQLALCHEMY_DATABASE_URI = 'mysql+mysqlconnector://root:pcb.2176310315865259@localhost:3306/employees'
# Enable this for PostgreSQL.
# SQLALCHEMY_DATABASE_URI = 'postgresql+psycopg2://postgres:pcb.2176310315865259@localhost/employees'
class Employees(WriteCapableTable):
__tablename__ = 'employees'
emp_no = Column(Integer, primary_key=True)
birth_date = Column(Date, nullable=False)
first_name = Column(String(14), nullable=False)
last_name = Column(String(16), nullable=False)
gender = Column(String(1), nullable=False)
hire_date = Column(Date, nullable=False)
def select_by_partial_last_name_and_first_name(self,
last_name: str, first_name: str) -> ResultStatus:
return self.run_stored_proc('get_employees', [last_name, first_name], True)
def create_app(config=None):
"""Construct the core application."""
app = flask.Flask(__name__, instance_relative_config=False)
init_extensions(app)
init_app_database(app)
return app
def init_extensions(app):
app.url_map.strict_slashes = False
def init_app_database(app):
Database.disconnect()
Database.connect(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_DATABASE_SCHEMA)
app = create_app()
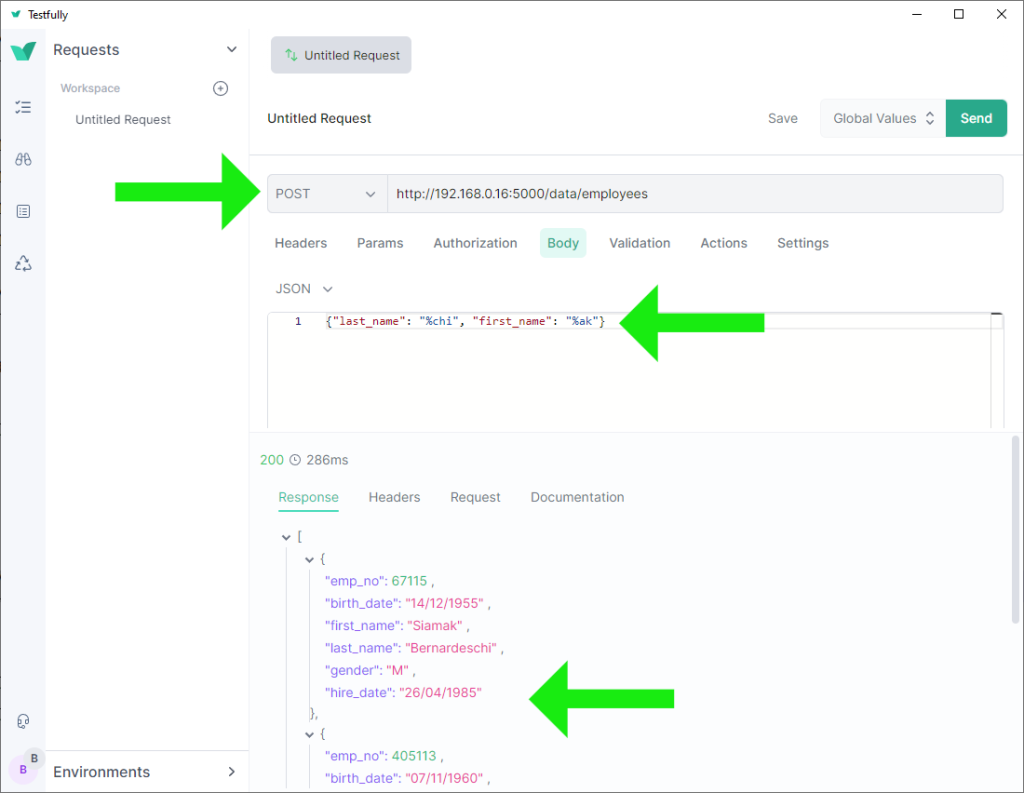
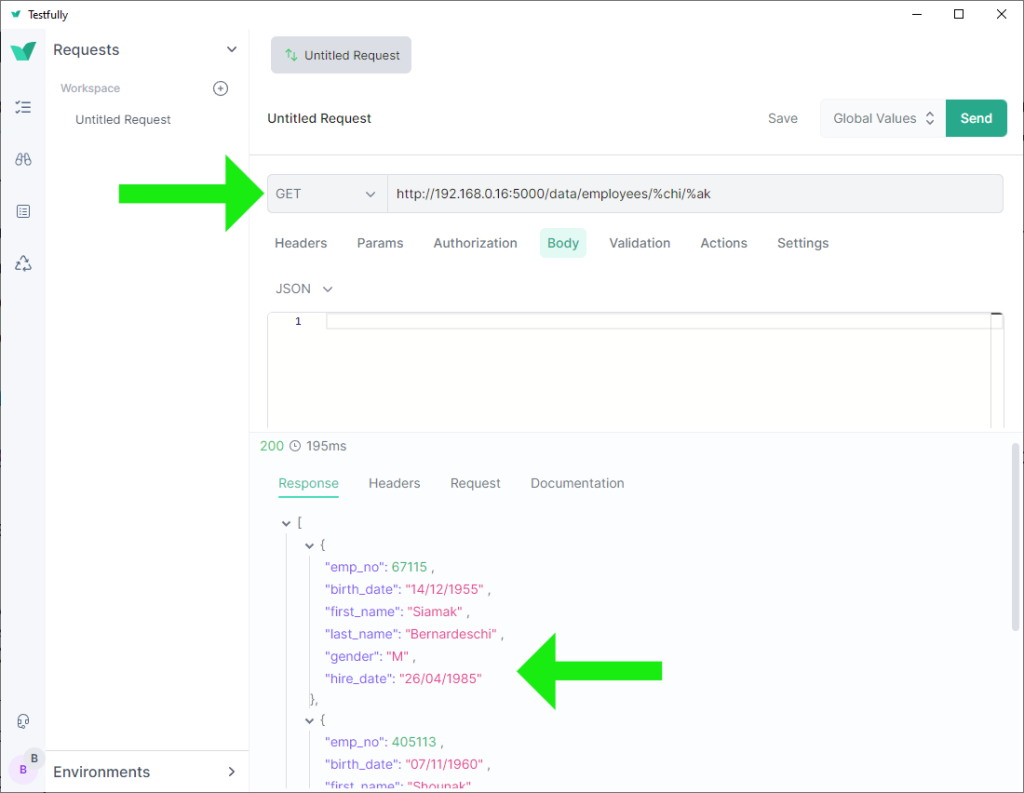
@app.get('/employees/search/<last_name>/<first_name>')
def search_employees(last_name: str, first_name: str) -> dict:
""" last_name and first_name are partial using %.
An example of a valid route: http://localhost:5000/employees/search/%nas%/%An
"""
return Employees() \
.select_by_partial_last_name_and_first_name(last_name, first_name) \
.as_dict()
if __name__ == '__main__':
app.run()
To execute the example.py application:
▶️Windows 10:(venv) F:\bh_database\examples\flaskr>venv\Scripts\flask.exe --app example run --host 0.0.0.0 --port 5000 ▶️Ubuntu 22.10:(venv) behai@hp-pavilion-15:~/bh_database/examples/flaskr$ venv/bin/flask --app example run --host 0.0.0.0 --port 5000
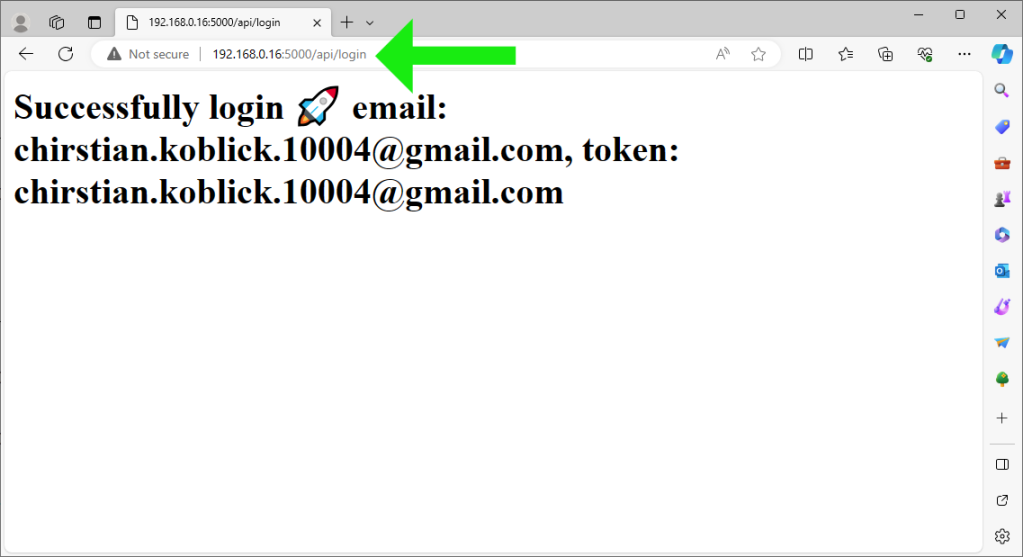
Accessing the example.py application running locally from Windows 10:
http://localhost:5000/employees/search/%nas%/%An
Accessing the example.py application running on Ubuntu 22.10 from Windows 10:
http://192.168.0.16:5000/employees/search/%nas%/%An
❷ example.py: A Simple Single-Module
FastAPI Application.
● Windows 10: F:\bh_database\examples\fastapir\example.py
● Ubuntu 22.10: /home/behai/bh_database/examples/fastapir/example.py
from sqlalchemy import (
Column,
Integer,
Date,
String,
)
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from bh_database.core import Database
from bh_database.base_table import WriteCapableTable
from bh_apistatus.result_status import ResultStatus
SQLALCHEMY_DATABASE_SCHEMA = 'employees'
SQLALCHEMY_DATABASE_URI = 'mysql+mysqlconnector://root:pcb.2176310315865259@localhost:3306/employees'
# Enable this for PostgreSQL.
# SQLALCHEMY_DATABASE_URI = 'postgresql+psycopg2://postgres:pcb.2176310315865259@localhost/employees'
class Employees(WriteCapableTable):
__tablename__ = 'employees'
emp_no = Column(Integer, primary_key=True)
birth_date = Column(Date, nullable=False)
first_name = Column(String(14), nullable=False)
last_name = Column(String(16), nullable=False)
gender = Column(String(1), nullable=False)
hire_date = Column(Date, nullable=False)
def select_by_partial_last_name_and_first_name(self,
last_name: str, first_name: str) -> ResultStatus:
return self.run_stored_proc('get_employees', [last_name, first_name], True)
app = FastAPI()
Database.disconnect()
Database.connect(SQLALCHEMY_DATABASE_URI, SQLALCHEMY_DATABASE_SCHEMA)
@app.get("/employees/search/{last_name}/{first_name}", response_class=JSONResponse)
async def search_employees(last_name: str, first_name: str):
""" last_name and first_name are partial using %.
An example of a valid route: http://localhost:5000/employees/search/%nas%/%An
"""
return Employees() \
.select_by_partial_last_name_and_first_name(last_name, first_name) \
.as_dict()
To execute the example.py application:
▶️Windows 10:(venv) F:\bh_database\examples\fastapir>venv\Scripts\uvicorn.exe example:app --host 0.0.0.0 --port 5000 ▶️Ubuntu 22.10:(venv) behai@hp-pavilion-15:~/bh_database/examples/fastapir$ venv/bin/uvicorn example:app --host 0.0.0.0 --port 5000
Accessing the example.py application running locally from Windows 10:
http://localhost:5000/employees/search/%nas%/%An
Accessing the example.py application running on Ubuntu 22.10 from Windows 10:
http://192.168.0.16:5000/employees/search/%nas%/%An
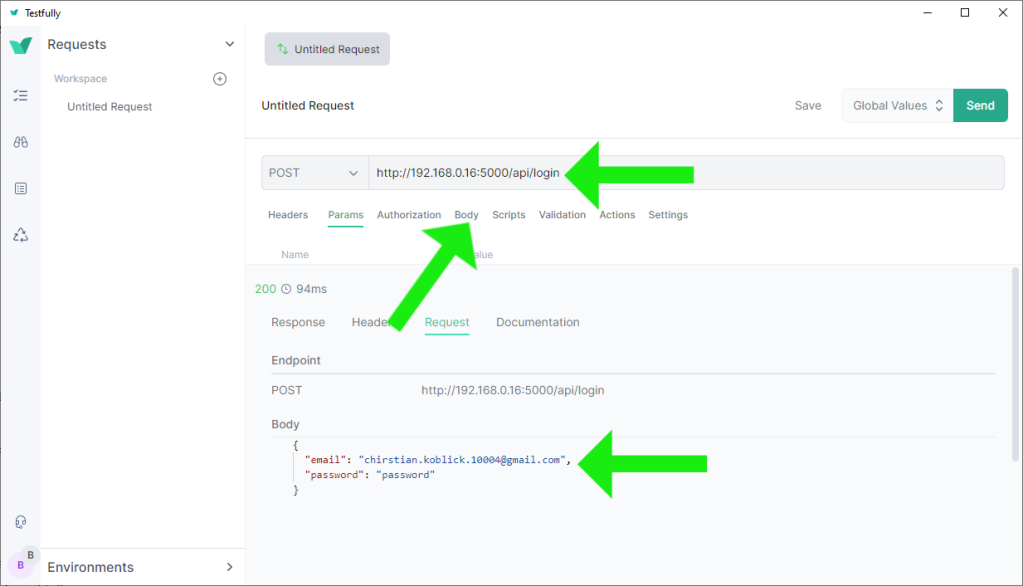
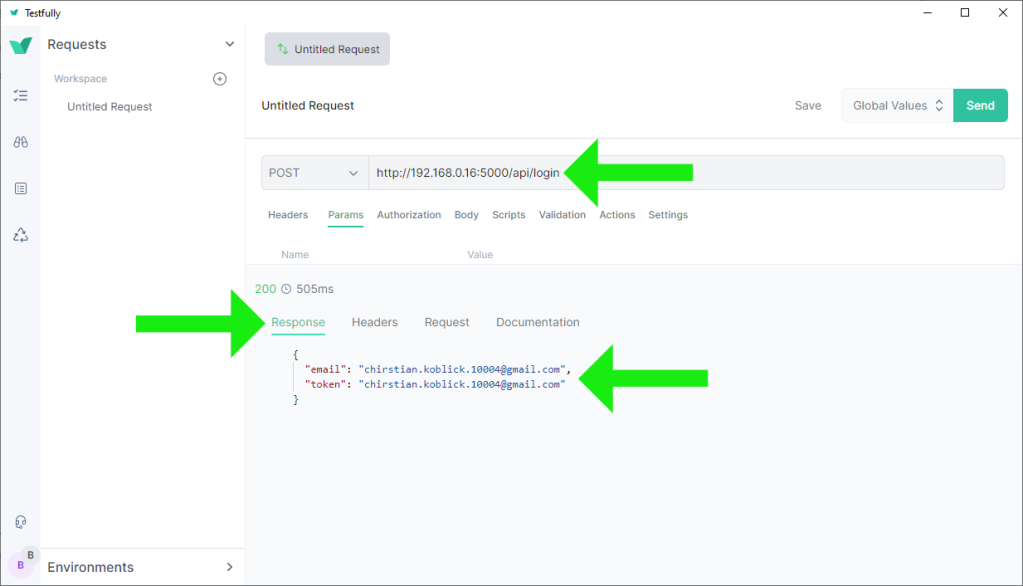
❸ A more comprehensive Flask application: a fully documented web server example with CRUD operations.
Please refer to https://github.com/behai-nguyen/bh_database/tree/main/examples/flaskr for the full source code, instructions on setting up the environment, installing packages, running tests, and finally running the application.
The layout of the example project is as follows:
/home/behai/bh_database/examples/flaskr
├── app.py
├── .env
├── pyproject.toml
├── pytest.ini
├── README.md
├── src
│ └── flaskr
│ ├── business
│ │ ├── app_business.py
│ │ ├── base_business.py
│ │ ├── base_validation.py
│ │ ├── employees_mgr.py
│ │ └── employees_validation.py
│ ├── config.py
│ ├── controllers
│ │ └── employees_admin.py
│ ├── __init__.py
│ ├── models
│ │ └── employees.py
│ ├── static
│ │ └── styles.css
│ └── templates
│ ├── admin
│ │ ├── emp_edit.html
│ │ ├── emp_search.html
│ │ └── emp_search_result.html
│ └── base.html
└── tests
├── business
│ └── test_employees_mgr.py
├── conftest.py
├── __init__.py
├── integration
│ └── test_employees_itgt.py
└── unit
└── test_employees.py❹ A more comprehensive FastAPI application: a fully documented web server example with CRUD operations.
Please refer to https://github.com/behai-nguyen/bh_database/tree/main/examples/fastapir for the full source code, instructions on setting up the environment, installing packages, running tests, and finally running the application.
The layout of the example project is as follows:
/home/behai/bh_database/examples/fastapir
├── .env
├── main.py
├── pyproject.toml
├── pytest.ini
├── README.md
├── src
│ └── fastapir
│ ├── business
│ │ ├── app_business.py
│ │ ├── base_business.py
│ │ ├── base_validation.py
│ │ ├── employees_mgr.py
│ │ └── employees_validation.py
│ ├── config.py
│ ├── controllers
│ │ ├── employees_admin.py
│ │ └── __init__.py
│ ├── __init__.py
│ ├── models
│ │ └── employees.py
│ ├── static
│ │ └── styles.css
│ └── templates
│ ├── admin
│ │ ├── emp_edit.html
│ │ ├── emp_search.html
│ │ └── emp_search_result.html
│ └── base.html
└── tests
├── business
│ └── test_employees_mgr.py
├── conftest.py
├── __init__.py
├── integration
│ └── test_employees_itgt.py
└── unit
└── test_employees.py💥 Except for the framework-specific layer code, the remaining code in these two examples is very similar.
Let’s briefly discuss their similarities:
-
/modelsand/businesscode are identical. They could be shared across both examples, but I prefer to keep each example self-contained. -
/tests/unitand/tests/businesscode are identical.
And there are differences in the following areas:
-
/controllers: This is the web layer, which is framework-specific, so understandably they are different. -
/tests/integration: The sole difference is framework-specific: how the HTTP response value is extracted:-
Flask:response.get_data(as_text=True) -
FastAPI:response.text
-
-
/tests/conftest.py: This file is framework-dependent. Both modules return the same fixtures, but the code has nothing in common. -
/templates/base.html: There is one difference:-
Flask:<link rel="stylesheet" href="{{ url_for('static', filename='styles.css') }}"> -
FastAPI:<link rel="stylesheet" href="{{ url_for('static', path='/styles.css') }}">
That is,
Flaskusesfilename, whileFastAPIusespath. -
The /controllers layer is thin in the sense that the code is fairly short; it simply takes the client-submitted data and passes it to the business layer to handle the work. The business layer then forwards the validated data to the database layer, and so on. The differences between the two implementations are minor.
It has been an interesting exercise developing this wrapper component.
The fact that it seamlessly integrates with the
FastAPI
framework is just a bonus for me; I didn’t plan for it since I hadn’t
learned FastAPI at the time. I hope you find this post useful.
Thank you for reading, and stay safe as always.
✿✿✿
Feature image source:
- https://www.omgubuntu.co.uk/2022/09/ubuntu-2210-kinetic-kudu-default-wallpaper
- https://in.pinterest.com/pin/337277459600111737/
- https://quintagroup.com/cms/python/images/sqlalchemy-logo.png/view
- https://www.logo.wine/logo/MySQL
- https://icon-icons.com/download/170836/PNG/512/
- https://flask.palletsprojects.com/en/3.0.x/